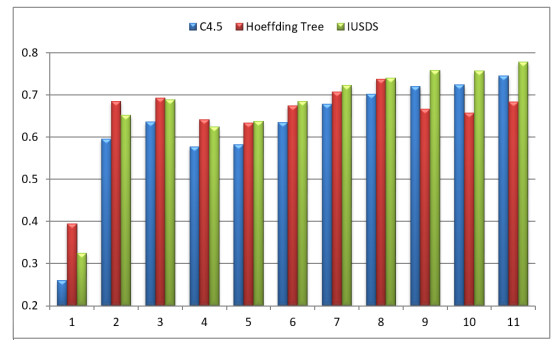
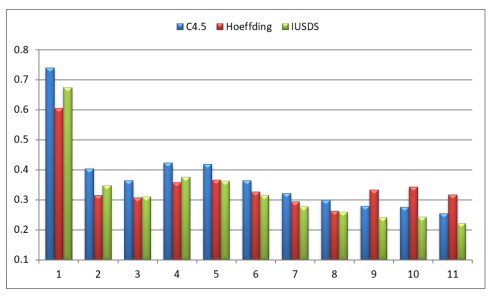
Data stream mining is every popular in recent years with advanced electronic devices generating continuous data streams. The performance of standard learning algorithms has been compromised with imbalance nature present in real world data streams. In this paper, we propose an algorithm known as Increment Under Sampling for Data streams (IUSDS) which uses an unique under sampling technique to almost balance the data sets to minimize the effect of imbalance in stream mining process. The experimental analysis conducted suggests that the proposed algorithm improves the knowledge discovery over benchmark algorithms like C4.5 and Hoeffding tree in terms of standard performance measures namely accuracy, AUC, precision, recall, F-measure, TP rate, FP rate and TN rate.
Citation: Anupama N, Sudarson Jena. A novel approach using incremental under sampling for data stream mining[J]. Big Data and Information Analytics, 2018, 3(1): 1-13. doi: 10.3934/bdia.2017017
Data stream mining is every popular in recent years with advanced electronic devices generating continuous data streams. The performance of standard learning algorithms has been compromised with imbalance nature present in real world data streams. In this paper, we propose an algorithm known as Increment Under Sampling for Data streams (IUSDS) which uses an unique under sampling technique to almost balance the data sets to minimize the effect of imbalance in stream mining process. The experimental analysis conducted suggests that the proposed algorithm improves the knowledge discovery over benchmark algorithms like C4.5 and Hoeffding tree in terms of standard performance measures namely accuracy, AUC, precision, recall, F-measure, TP rate, FP rate and TN rate.

| [1] | Alcalá-Fdez J., Fernandez A., Luengo J., Derrac J., García S., Sánchez L., Herrera F. (2011) KEEL data-mining software tool: Data set repository, Integration of Algorithms and Experimental Analysis Framework. Journal of Multiple-Valued Logic and Soft Computing 17: 255-287. |
| [2] | A. Asuncion and D. J. Newman, UCI Repository of Machine Learning Database (School of Information and Computer Science), Irvine, CA: Univ. of California [Online], 2007. Available: http://www.ics.uci.edu/mlearn/MLRepository.html |
| [3] |
Brown I., Mues C. (2012) An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Systems with Applications 39: 3446-3453. doi: 10.1016/j.eswa.2011.09.033

|
| [4] |
Cao P., Zhao D., Zaiane O. (2013) A PSO-based cost-sensitive neural network for imbalanced data classification. Trends and Applications in Knowledge Discovery and Data Mining 452-463. doi: 10.1007/978-3-642-40319-4_39
|
| [5] | Y. Chen, Learning Classifiers from Imbalanced Only Positive and Unlabeled Data Sets 2008 UC San Diego Data Mining Contest. |
| [6] |
Chen Y., Tang S., Zhou L., Wang C., Du J., Wang T., Pei S. (2018) Decentralized Clustering by Finding Loose and Distributed Density Cores. Inform. Sci. 433/434: 510-526. doi: 10.1016/j.ins.2016.08.009
|
| [7] | Doucette, Heywood M. I. (2008) Classification under imbalanced data sets:Active sub-sampling and auc approximation. M. O'Neill et al. Eds.:EuroGP 2008, LNCS 4971: 266-277. |
| [8] |
Frey B. J., Dueck D. (2007) Clustering by passing messages between data points. Science 315: 972-976. doi: 10.1126/science.1136800
|
| [9] |
G. Hulten, L. Spencer and P. Domingos, Mining time-changing data streams, In: ACM
SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining, (2001), 97-106.
10.1145/502512.502529 |
| [10] |
Jain A. K. (2008) Data clustering:50 years beyond K-means. Part of the Lecture Notes in Computer Science book series 5211: 3-4. doi: 10.1007/978-3-540-87479-9_3
|
| [11] | R. Kohavi, Scaling up the accuracy of Naive-Bayes classifiers: A decision-tree hybrid, In: Second International Conference on Knoledge Discovery and Data Mining, (1996), 202-207. |
| [12] |
López V., Triguero I., Carmona C. J., García S., Herrera F. (2014) Addressing imbalanced classification withinstance generation techniques: IPADE-ID. Neurocomputing 126: 15-28. doi: 10.1016/j.neucom.2013.01.050
|
| [13] |
Lorena A. C., Jacintho L. F. O., Siqueira M. F., De Giovanni R., Lohmann L. G., de Carvalho A. C. P. L. F., Yamamoto M. (2011) Comparing machine learning classifiers in potential distribution modelling. Expert Systems with Applications 38: 5268-5275. doi: 10.1016/j.eswa.2010.10.031
|
| [14] | H. Ma, Correlation-based Feature Subset Selection For Machine Learning PhD Thesis, 1998. |
| [15] | A. K. Menon, H. Narasimhan, S. Agarwal and S. Chawla, On the statistical consistency of algorithms for binary classification under class imbalance, Appearing in Proceedings of the 30 thInternational Conference on Machine Learning Atlanta, Georgia, USA, 2013. |
| [16] |
Rodriguez A., Laio A. (2014) Clustering by fast search and find of density peaks. Science 344: 1492-1496. doi: 10.1126/science.1242072
|
| [17] |
Verbiesta N., Ramentol E., Cornelisa C., Herrera F. (2014) Preprocessing noisy imbalanced datasets using SMOTE enhanced withfuzzy rough prototype selection. Applied Soft Computing 22: 511-517. doi: 10.1016/j.asoc.2014.05.023
|
| [18] |
Wang S., Minku L. L., Yao X. (2015) Resampling-based ensemble methods for online class imbalance learning. IEEE Transactions on Knowledge and Data Engineering 27: 1356-1368. doi: 10.1109/TKDE.2014.2345380
|
| [19] |
Witten I. H., Frank E. (2002) Data mining:Practical machine learning tools and techniques. Newsletter: ACM SIGMOD Record Homepage Archive 31: 76-77. doi: 10.1145/507338.507355
|
| [20] | B. Yang and L. Jing, A Novel nonparallel plane proximal svm for imbalance data classification Journal of Software, 9 2014. |
Figures(2) / Tables(11)

Anupama N, Sudarson Jena. A novel approach using incremental under sampling for data stream mining[J]. Big Data and Information Analytics, 2018, 3(1): 1-13. doi: 10.3934/bdia.2017017









 DownLoad:
DownLoad: