Citation: Andrea Somogyi, Cristian Mocuta. Possibilities and Challenges of Scanning Hard X-ray Spectro-microscopy Techniques in Material Sciences[J]. AIMS Materials Science, 2015, 2(2): 122-162. doi: 10.3934/matersci.2015.2.122

| [1] |
Bordiga S, Groppo E, Agostini G, et al. (2013) Reactivity of surface species in heterogeneous catalysts probed by in situ x-ray absorption techniques. Chem Rev 113: 1736-1850. doi: 10.1021/cr2000898

|
| [2] |
Hrauda N, Zhang J, Wintersberger E, et al. (2011) X-ray Nanodiffraction on a Single SiGe Quantum Dot inside a Functioning Field-Effect Transistor. Nano Lett 11: 2875-2880. doi: 10.1021/nl2013289
|
| [3] | Buurmans ILC, Weckhuysen BM (2012). Space and time as monitored by spectroscopy, Nature Chemistry 4:873-886. |
| [4] |
Hitchcock AP, Johansson GA, Mitchell GH, et al. (2008). 3-d chemical imaging using angle-scan nanotomography in a soft X-ray scanning transmission X-ray microscope. Appl Phys A 92:447-452. doi: 10.1007/s00339-008-4588-x
|
| [5] | Hitchcock AP (2012) Soft X-Ray Imaging and Spectromicroscopy, in Handbook of Nanoscopy, Volume 1&2 (eds G. Van Tendeloo, D. Van Dyck and S. J. Pennycook), Wiley-VCH Verlag GmbH & Co. KGaA, Weinheim, Germany. |
| [6] |
Ade H, Stoll H (2009) Near-edge X-ray absorption fine-structure microscopy of organic and magnetic materials. Nature Materials 8: 281-290. doi: 10.1038/nmat2399
|
| [7] |
Kaulich B, Thibault P, Gianoncelli A, et al. (2011) Transmission and emission x-ray microscopy: operation modes, contrast mechanisms and applications. J Phys Cond Matter 23: 083002. doi: 10.1088/0953-8984/23/8/083002
|
| [8] |
Beale AM, Jacques SDM, & Weckhuysen BM (2010). In-situ characterization of heterogeneous catalysts themed issue Chemical imaging of catalytic solids with synchrotron radiation. Chem Soc Rev 39: 4656-4672. doi: 10.1039/c0cs00089b
|
| [9] |
Harris WM, Nelson GJ, Kiss A, at al. (2012) Nondestructive volumetric 3-D chemical mapping of nickel-sulfur compounds at the nanoscale. Nanoscale 4: 1557-1560. doi: 10.1039/c2nr11690a
|
| [10] | Wang J, Chen-wiegart YK, Wang J, (2014) In operando tracking phase transformation evolution of lithium iron phosphate with hard X-ray microscopy. Nature Com 5: 1. |
| [11] |
Fenter P, Park C, Zhang Z, et al. (2006) Observation of Sub-nm-High Surface Topography with X-ray Reflection Phase-Contrast Microscopy. Nat Phys 2: 700-704. doi: 10.1038/nphys419
|
| [12] |
Fenter P, Park C, Kohli V, et al. (2008) Image contrast in X-ray reflection interface microscopy: comparison of data with model calculations and simulations. J Synch Rad 15: 558-571. doi: 10.1107/S0909049508023935
|
| [13] |
Fister TT, Goldman JL, Long BR, et al. (2013) X-ray diffraction microscopy of lithiated silicon microstructures. Appl Phys Lett 102: 131903. doi: 10.1063/1.4798554
|
| [14] |
Hilhorst J, Marschall F, Tran Thi TN, et al. (2014) Full-field X-ray diffraction microscopy using polymeric compound refractive lenses. J Appl Cryst 47: 1882-1888. doi: 10.1107/S1600576714021256
|
| [15] |
Mocuta C, Barbier A, Stanescu S, et al. (2013) X-ray diffraction imaging of metal-oxide epitaxial tunnel junctions made by optical lithography: use of focused and unfocused X-ray beams. J Synch Rad 20: 355-365. doi: 10.1107/S090904951204856X
|
| [16] |
Luebbert D, Baumbach T, Hartwig J, et al. (2000) μm-resolved high resolution X-ray diffraction imaging for semiconductor quality control. Nucl Meth Phys Res B160:521-527. doi: 10.1016/S0168-583X(99)00619-9
|
| [17] |
Ice GE, Budai JD, Pang JWL (2011) The Race to X-ray Microbeam and Nanobeam Science. Science 334: 1234-1239. doi: 10.1126/science.1202366
|
| [18] | Stangl J, Mocuta C, Chamard V, et al. (2014) Nanobeam X-ray Scattering—Probing matter at the Nanoscale. Wiley VCH WileyBook. |
| [19] |
Johannes A, Noack SJrWP, Kumar S, et al. (2014) Enhanced sputtering and incorporation of Mn in implanted GaAs and ZnO nanowires. J Phys D Appl Phys 47: 394003. doi: 10.1088/0022-3727/47/39/394003
|
| [20] |
Segura-Ruiz J, Martinez-Criado G, Chu MH, et al. (2013) Synchrotron nanoimaging of single In-rich InGaN nanowires. J Appl Phys 113: 136511. doi: 10.1063/1.4795544
|
| [21] | Stangl J, Mocuta C, Diaz A, et al. (2009) X-Ray Diffraction as a Local Probe Tool. Chem Phys Chem 10: 2923-2930. |
| [22] |
Maser J, Lai B, Buonassisi T, et al. (2014) A Next-Generation Hard X-Ray Nanoprobe Beamline for In Situ Studies of Energy Materials and Devices. Metall Mater Trans A 45: 85-97. doi: 10.1007/s11661-013-1901-x
|
| [23] | Martinez-Criado G, Segura-Ruiz J, Alén B, et al. (2014) Exploring single semiconductor nanowires with a multimodal hard X-ray nanoprobe. Adv Mater 1-7. |
| [24] | Holt M, Harder R, Winarski R, et al. (2013) Nanoscale Hard X-ray Microscopy Methods for Materials Studies. Annu Rev Mater Res 43: 3.1-3.29. |
| [25] |
Weker JN, Toney MF (2015) Emerging In Situ and Operando Nanoscale X-Ray Imaging Techniques for Energy Storage Materials. Adv Func Mat 25: 1622-1637. doi: 10.1002/adfm.201403409
|
| [26] |
Sirenko AA, Reynolds CL, Peticolas LJ, et al. (2003) Micro-X-ray fluorescence and micro-photoluminescence in InGaAsP and InGaAs layers obtained by selective area growth. J Crystal Growth 253: 38-45. doi: 10.1016/S0022-0248(03)00996-5
|
| [27] |
Mino L, Agostino A, Codato S, et al. (2010) Study of epitaxial selective area growth In1-xGaxAs films by synchrotron µ-XRF mapping. J Anal At Spectrom 25: 831-836. doi: 10.1039/c000435a
|
| [28] |
Buonassisi T, Istratov AA, Marcus MA, et al. (2005) Engineering metal-impurity nanodefects for low-cost solar cells. Nature Materials 4: 676-679. doi: 10.1038/nmat1457
|
| [29] | Kwapil W, Gundel P, Schubert MC, et al. (2009) Observation of metal precipitates at prebreakdown sites in multicrystalline silicon solar cells. Appl Phys Lett 95:23-25. |
| [30] |
Bertoni MI, Fenning DP, Rinio M, et al. (2011) Nanoprobe X-ray fluorescence characterization of defects in large-area solar cells. Energy Environ Sci 4: 4252-4257. doi: 10.1039/c1ee02083h
|
| [31] |
Hu Q, Aboustait M, Ley MT, et al. (2014) Combined three-dimensional structure and chemistry imaging with nanoscale resolution. Acta Materialia 77: 173-182. doi: 10.1016/j.actamat.2014.05.050
|
| [32] |
Mino L, Agostini G, Borfecchia E, et al. (2013) Low-dimensional systems investigated by x-ray absorption spectroscopy: a selection of 2D, 1D and 0D cases. J Phys D: Appl Phys 46: 423001. doi: 10.1088/0022-3727/46/42/423001
|
| [33] | Martinez-Criado G, Segura-Ruiz J, Chu M, et al. (2014a) Crossed Ga2O3/SnO2 Multiwire Architecture: A Local Structure Study with Nanometer Resolution. Nano Letters 14: 5479-5487. |
| [34] |
Larcheri S, Rocca F, Pailharey D, et al. (2009) A new tool for nanoscale X-ray absorption spectroscopy and element-specific SNOM microscopy. Micron 40: 61-65. doi: 10.1016/j.micron.2008.01.020
|
| [35] |
Shirato N, Cummings M, Kersell H, et al. (2014) Elemental Fingerprinting of Materials with Sensitivity at the Atomic Limit. Nano Letters 14: 6499-6504. doi: 10.1021/nl5030613
|
| [36] | Mocuta C, Stangl J, Mundboth K, et al. (2008) Beyond the ensemble average: X-ray microdiffraction analysis of single SiGe islands. Phys Rev B77: 245425. |
| [37] |
Bleuet P, Cloetens P, Gergaud P, et al. (2009) A hard x-ray nanoprobe for scanning and projection nanotomography. Rev Sci Inst 80: 056101. doi: 10.1063/1.3117489
|
| [38] |
Bunk O, Bech M, Jensen TH, et al. (2009) Multimodal x-ray scatter imaging. New J Phys 11: 123016. doi: 10.1088/1367-2630/11/12/123016
|
| [39] |
Meirer F, Cabana J, Liu Y, et al. (2011) Three-dimensional imaging of chemical phase transformations at the nanoscale with full-field transmission X-ray microscopy. J Synch Rad 18: 773-781. doi: 10.1107/S0909049511019364
|
| [40] |
Villanova J, Segura-Ruiz J, Lafford T, et al. (2012) Synchrotron microanalysis techniques applied to potential photovoltaic materials. J Sync Rad 19: 521-524. doi: 10.1107/S0909049512021383
|
| [41] |
Gómez-Gómez M, Garro N, Segura-Ruiz J, et al. (2014) Spontaneous core-shell elemental distribution in In-rich InxGa1-xN nanowires grown by molecular beam epitaxy. Nanotechnology 25: 075705. doi: 10.1088/0957-4484/25/7/075705
|
| [42] | Tsuji K, Injuk J, Van Grieken R (2004) X-ray spectrometry: recent technological advances. John Wiley & Sons, Ltd. |
| [43] | Hippert F, Geissler E, Hodeau JL, et al. (eds) (2006) Neutron and X-ray spectroscopy. Springer. |
| [44] | Van Grieken R, Markowicz A (2001) Handbook of X-Ray Spectrometry. CRC Press. |
| [45] | Somogyi A, Medjoubi K, Baranton G, et al. (2015). Optical design and multi-length-scale scanning spectro-microscopy possibilities at the Nanoscopium beamline of Synchrotron Soleil. J Synch Rad. In press |
| [46] |
Schroer CG (2001) Reconstructing x-ray fluorescence microtomograms. Appl Phys Lett 79: 1912. doi: 10.1063/1.1402643
|
| [47] |
Golosio B, Somogyi A, Simionovici A, et al. (2004) Nondestructive three-dimensional elemental microanalysis by combined helical x-ray microtomographies. Appl Phys Lett 84: 2199. doi: 10.1063/1.1686892
|
| [48] |
Bleuet P, Gergaud P, Lemelle L, et al. (2010) 3D chemical imaging based on a third-generation synchrotron source. TrAC-Trends in Anal Chem 29: 518-527. doi: 10.1016/j.trac.2010.02.011
|
| [49] | De Jonge MD, Vogt S,(2010) Hard X-ray fluorescence tomography-an emerging tool for structural visualization. Curr Opin Struct Biol 20: 606. |
| [50] | Kak AC, Slaney M (2001) Principles of Computerized Tomographic Imaging. Philadelphia: Society for Industrial and Applied Mathematics.(an abridged republication of the work first published by IEEE Press, New York, 1988). |
| [51] |
Golosio B, Simionovici A, Somogyi A, et al. (2003) Internal elemental microanalysis combining XRF, Compton and Transmission Tomography. J Appl Phys 94: 145. doi: 10.1063/1.1578176
|
| [52] |
Naghedolfeizi M, Chung J, Morris R, et al. (2003) X-ray fluorescence microtomography study of trace elements in a SiC nuclear fuel shell. J Nucl Mater 312: 146-155. doi: 10.1016/S0022-3115(02)01681-1
|
| [53] |
Lombi E, De Jonge MD, Donner E, et al. (2011) Fast X-ray fluorescence microtomography of hydrated biological samples. PLoS ONE 6: e20626. doi: 10.1371/journal.pone.0020626
|
| [54] |
Medjoubi K, Leclercq N, Langlois F, et al. (2013) Development of fast, simultaneous and multi-technique scanning hard X-ray microscopy at Synchrotron Soleil. J Synch Rad 20: 293-300. doi: 10.1107/S0909049512052119
|
| [55] | Medjoubi K, Bonissent A, Leclercq N, et al. (2013) Simultaneous fast scanning XRF, dark field, phase-, and absorption contrast tomography. Proceedings of SPIE, 2013, 8851:art.n° 88510P |
| [56] |
Vincze L, Vekemans B, Brenker FE (2004) Three-Dimensional Trace Element Analysis by Confocal X-ray Microfluorescence Imaging. Anal Chem 76: 6786. doi: 10.1021/ac049274l
|
| [57] | Lamberti C, Agostini G, (2013) Characterization of Semiconductor Heterostructures and Nanostructures 2nd edn, ed C Lamberti, G Agostini (Amsterdam: Elsevier). |
| [58] | Calvin S (2013) XAFS for Everyone. Boca Raton FL: Taylor and Francis. |
| [59] | Schnohr CS, Ridgway MC (Eds.) (2015) X-Ray Absorption Spectroscopy of semiconductors, Series: Springer Series in Optical Sciences, Vol. 190 (Springer) |
| [60] | Martinez-Criado G, Somogyi A, Homs A, et al. (2005a) Micro-x-ray absorption near-edge structure imaging for detecting metallic Mn in GaN. Appl Phys Lett 87: 061913. |
| [61] |
Seifert W, Vyvenko O, Arguirov T, et al. (2009) Synchrotron-based investigation of iron precipitation in multicrystalline silicon. Superlattice Microst 45: 168-176. doi: 10.1016/j.spmi.2008.11.025
|
| [62] |
Watts B, McNeil C (2010) Simultaneous Surface and Bulk Imaging of Polymer Blends with X-ray Spectromicroscopy. Macromolec Rapid Commun 31: 1706-1712. doi: 10.1002/marc.201000269
|
| [63] |
Watts B, McNeil C, Raabe J (2012) Imaging nanostructures in organic Semiconductor films with scanning transmission X-ray spectro-microscopy. Synthetic Met 161: 2516-2520. doi: 10.1016/j.synthmet.2011.09.016
|
| [64] |
d’Acapito F (2015) Group III-V and II-VI Nanowires in X-Ray Absorption Spectroscopy of Semiconductors. Springer Series in Optical Sciences 190: 269-286. doi: 10.1007/978-3-662-44362-0_13
|
| [65] | Strachan JP, Medeiros-Ribeiro G, Yang JJ, et al. (2011) Spectromicroscopy of tantalum oxide memristors. Appl Phys Lett 98: 24-26. |
| [66] |
Rau C, Somogyi A, Simionovici A (2003) Microimaging and tomography with chemical speciation. Nucl Instr Methods Phys Res B 200: 444-450. doi: 10.1016/S0168-583X(02)01737-8
|
| [67] |
Segura-Ruiz J, Martinez-Criado G, Chu MH, et al. (2011) Nano-X-ray Absorption Spectroscopy of Single Co-Implanted ZnO Nanowires. Nano Letters 11: 5322-5326. doi: 10.1021/nl202799e
|
| [68] |
Wang J, Chen-Wiegart YK, Wang J (2013) In situ chemical mapping of a lithium-ion battery using full-field hard X-ray spectroscopic imaging. Chem Com 49: 6480-6482. doi: 10.1039/c3cc42667j
|
| [69] |
Rosenberg RA, Shenoy GK, Sun XH, et al. (2006) Time-resolved x-ray-excited optical luminescence characterization of one-dimensional Si—CdSe heterostructures. Appl Phys Lett 89: 243102. doi: 10.1063/1.2402262
|
| [70] |
O’Malley SM, Revesz P, Kazimirov A, et al. (2011) Time-resolved x-ray excited optical luminescence in InGaN / GaN multiple quantum well structures. J Appl Phys 109: 124906. doi: 10.1063/1.3598137
|
| [71] | Bianconi A, Jackson D (1978) Intrinsic luminescence excitation spectrum and extended x-ray absorption fine structure above the K edge in CaF2. Phys Rev A 17: 2021-2024. |
| [72] | Goulon J, Tola P, Lemonnier M, et al. (1983) On a site-selective EXAFS experiment using optical emission, Chem. Phys. 78: 347-356. |
| [73] | Rogalev A, & Goulon J (2002) X-ray excited optical luminescence spectroscopies, Advanced Series in Physical Chemistry: Volume 12, Chemical Applications of Synchrotron Radiation, Edited by: Sham TK, 707-760. World Scientific. |
| [74] | Sham TK, Naftel SJ, Kim PG, et al. (2004) Electronic structure and optical properties of silicon nanowires : A study using x-ray excited optical luminescence and x-ray emission spectroscopy, Phys Rev B70:045313. |
| [75] |
Hanke M, Dubslaff M, Schmidbauer M, et al. (2008) Scanning x-ray diffraction with 200 nm spatial resolution. Appl Phys Lett 92: 193109. doi: 10.1063/1.2929374
|
| [76] |
Diaz A, Mocuta C, Stangl J, et al. (2009) Spatially resolved strain within a single SiGe island investigated by X-ray scanning microdiffraction. Phys Stat Sol A 206: 1829-1832. doi: 10.1002/pssa.200881594
|
| [77] |
Mocuta C, Barbier A, Ramos AV, et al. (2007) Effect of optical lithography patterning on the crystalline structure of tunnel junctions. Appl Phys Lett 91: 241917. doi: 10.1063/1.2824858
|
| [78] |
Evans PG, Savage DE, Prance JR, et al. (2012) Nanoscale Distortions of Si Quantum Wells in Si/SiGe Quantum-Electronic Heterostructures. Adv Mater 24: 5217-5221. doi: 10.1002/adma.201201833
|
| [79] |
Chahine GA, Richard MI, Homs-Regojo RA, et al. (2014) Imaging of strain and lattice orientation by quick scanning X-ray microscopy combined with three dimensional reciprocal space mapping. J Appl Cryst 47: 762-769. doi: 10.1107/S1600576714004506
|
| [80] | Goodman JW (2005) Introduction to Fourier Optics, Roberts and Company Publishers |
| [81] |
Garcia-Sucerquia J, Xu W, Jericho SK, et al. (2006) Digital in-line holographic microscopy. Appl Opt 45: 836-850. doi: 10.1364/AO.45.000836
|
| [82] |
Leith EN, Upatniesks J (1962) Reconstructed Wavefronts and Communication Theory. J Opt Soc Am 52: 1123-1128. doi: 10.1364/JOSA.52.001123
|
| [83] |
Fuhse C, Ollinger C, Saldit T (2006) Waveguide-Based Off-Axis Holography with Hard X Rays. Phys Rev Lett 97: 254801. doi: 10.1103/PhysRevLett.97.254801
|
| [84] |
Eisebitt S, Luning J, Schlotter WF, et al. (2004) Lensless imaging of magnetic nanostructures by X-ray spectro-holography. Nature 432: 885-888. doi: 10.1038/nature03139
|
| [85] |
Stadler LM, Gutt C, Autenrieth T, et al. (2008) Hard X Ray Holographic Diffraction Imaging. Phys Rev Lett 100: 245503. doi: 10.1103/PhysRevLett.100.245503
|
| [86] |
Chamard V, Stangl J, Carbone D, et al. (2010) Three-Dimensional X-Ray Fourier Transform Holograhpy: The Bragg Case. Phys Rev Lett 104: 165501. doi: 10.1103/PhysRevLett.104.165501
|
| [87] |
Livet F (2007) Diffraction with a coherent X-ray beam: dynamics and imaging. Acta Crystallogr A 63: 87-107. doi: 10.1107/S010876730605570X
|
| [88] |
Miao J, Charalambous P, Kirz J, et al. (1999) Extending the methodology of X-ray crystallography to allow imaging of micrometre-sized non-crystalline specimens. Nature 400: 342-344. doi: 10.1038/22498
|
| [89] |
Miao J, Ishikawa T, Johnson B, et al. (2002) High Resolution 3D X-Ray Diffraction Microscopy. Phys Rev Lett 89: 088303. doi: 10.1103/PhysRevLett.89.088303
|
| [90] |
Takahashi T, Zettsu N, Nishino Y, et al. (2010) Three-Dimensional Electron Density Mapping of Shape-Controlled Nanoparticle by Focused Hard X-ray Diffraction Microscopy. Nano Lett 10: 1922-1926. doi: 10.1021/nl100891n
|
| [91] | Diaz A, Mocuta C, Stangl J, et al. (2009B) Coherent diffraction imaging of a single epitaxial InAs nanowire using a focused x-ray beam. Phys Rev B 79: 125324. |
| [92] |
Diaz A, Chamard V, Mocuta C, et al. (2010) Imaging the displacement field within epitaxial nanostructures by coherent diffraction: a feasibility study. New J Phys 12: 035006. doi: 10.1088/1367-2630/12/3/035006
|
| [93] |
Mastropietro F, Carbone D, Diaz A, et al. (2011) Coherent x-ray wavefront reconstruction of a partially illuminated Fresnel zone plate. Opt Express 19: 19223-19232. doi: 10.1364/OE.19.019223
|
| [94] |
Pfeiffer M, Williams GJ, Vartanyants IA, et al. (2006) Three-dimensional mapping of a deformation field inside a nanocrystal. Nature 442: 63-66. doi: 10.1038/nature04867
|
| [95] |
Robinson IK, Vartanyants IA, Williams GJ, et al. (2001) Reconstruction of the Shapes of Gold Nanocrystals Using Coherent X-Ray Diffraction. Phys Rev Lett 87: 195505. doi: 10.1103/PhysRevLett.87.195505
|
| [96] |
Newton MC, Leake SJ, Harder R, et al. (2010) Three-dimensional imaging of strain in a single ZnO nanorod. Nature Mater 9: 120-124. doi: 10.1038/nmat2607
|
| [97] |
Beutier G, Verdier M, Parry G, et al. (2013). Strain inhomogeneity in copper islands probed by coherent X-ray diffraction. Thin Solid Films 530: 120-124. doi: 10.1016/j.tsf.2012.02.032
|
| [98] |
Minkevich AA, Gailhanou M, Micha JS, et al. (2007) Inversion of the Diffraction Pattern from an Inhomogeneously Strained Crystal using an Iterative Algorithm. Phys Rev B 76: 104106. doi: 10.1103/PhysRevB.76.104106
|
| [99] |
Minkevich AA, Baumbach T, Gailhanou M, et al. (2008) Applicability of an iterative inversion algorithm to the diffraction patterns from inhomogeneously strained crystals. Phys Rev B 78: 174110. doi: 10.1103/PhysRevB.78.174110
|
| [100] |
Minkevich AA, Fohtung E, Slobodskyy T, et al. (2011) Strain field in (Ga,Mn)As/GaAs periodic wires revealed by coherent X-ray diffraction. European Phys Lett 94: 66001. doi: 10.1209/0295-5075/94/66001
|
| [101] |
Williams GJ, Quiney HM, Dhal BB, et al. (2006) Fresnel Coherent Diffractive Imaging. Phys Rev Lett 97: 025506. doi: 10.1103/PhysRevLett.97.025506
|
| [102] |
Quiney HM, Peele AG, Cai Z, et al. (2006) Diffractive imaging of highly focused X-ray fields. Nature Phys 2: 101-104. doi: 10.1038/nphys218
|
| [103] |
Faulkner HLM, Rodenberg JM (2004) Movable Aperture Lensless Transmission Microscopy: A Novel Phase Retrieval Algorithm. Phys Rev Lett 93: 023903. doi: 10.1103/PhysRevLett.93.023903
|
| [104] | Bunk O, Dierloff M, Kynde S, et al. (2007) Influence of the overlap parameter on the convergence of the ptychographical iterative engine. Ultramicroscopy 108: 481-487. |
| [105] |
Maiden A, Rodenburg J (2009) An improved ptychographical phase retrieval algorithm for diffractive imaging. Ultramicroscopy 109: 1256-1262. doi: 10.1016/j.ultramic.2009.05.012
|
| [106] |
Guizar-Sicairos M, Fineup J (2008) Phase retrieval with transverse translation diversity: a nonlinear optimization approach. Opt Express 16: 7264-7278. doi: 10.1364/OE.16.007264
|
| [107] |
Dierolf M, Menzel A, Thibault P, et al. (2010) Ptychographic X-ray computed tomography at the nanoscale. Nature 467: 436-439. doi: 10.1038/nature09419
|
| [108] |
Godard P, Carbone G, Allain M, et al. (2011) Three-dimensional high-resolution quantitative microscopy of extended crystals. Nature Commun 2: 568. doi: 10.1038/ncomms1569
|
| [109] | Godard P, Allain M, Chamard V, et al. (2011B) Imaging of highly inhomogeneous strain field in nanocrystals using x-ray Bragg ptychography: A numerical study. Phys Rev B 84: 144109. |
| [110] |
Korsunsky A, Hofmann F, Abbey B, et al. (2012) Analysis of the internal structure and lattice (mis) orientation in individual grains of deformed CP nickel polycrystals by synchrotron X-ray micro-diffraction and microscopy. Int J Fatigue 42: 1-13. doi: 10.1016/j.ijfatigue.2011.03.003
|
| [111] |
Georgiadis M, Guizar-sicairos M, Zwahlen A, et al. (2015).3D scanning SAXS: A novel method for the assessment of bone ultrastructure orientation. Bone 71: 42-52. doi: 10.1016/j.bone.2014.10.002
|
| [112] |
Snigirev A, Snigireva I, Kohn V, et al. (1995) On the possibilities of x-ray phase contrast microimaging by coherent high‐energy synchrotron radiation. Rev Sci Instrum 66: 5486. doi: 10.1063/1.1146073
|
| [113] | Cloetens P, Pateyron-Salomé M, Buffière J, et al. (1997) Observation of microstructure and damage in materials by phase sensitive radiography and tomography. J Appl Phys 81: 5. |
| [114] |
Pfeiffer M, Bech M, Bunk O, et al. (2008) Hard-X-ray dark-field imaging using a grating interferometer. Nature Mater 7: 134-137. doi: 10.1038/nmat2096
|
| [115] |
Weitkamp T, Diaz A, David C, et al. (2005) X-ray phase imaging with a grating interferometer. Opt Express 13: 6296. doi: 10.1364/OPEX.13.006296
|
| [116] |
David C, Nohammer B, Solak H, et al. (2002) Differential x-ray phase contrast imaging using a shearing interferometer. Appl Phys Lett 81: 3287. doi: 10.1063/1.1516611
|
| [117] |
Egan CK, Wilson MD, Veale MC, et al. (2014) Material specific X-ray imaging using an energy-dispersive pixel detector. Nucl Instrum Meth Phys Res B 324: 25-28. doi: 10.1016/j.nimb.2013.11.021
|
| [118] |
Ice GE, Specht ED (2012) Microbeam, timing and signal-resolved studies of nuclear materials with synchrotron X-ray sources. J Nucl Mat 425: 233-237. doi: 10.1016/j.jnucmat.2011.10.038
|
| [119] |
Singer A, Ulvestad A, Cho H, et al. (2014) Nonequilibrium Structural Dynamics of Nanoparticles in LiNi1/2Mn3/2O4 Cathode under Operando Conditions. Nano Lett 14: 5295-5300. doi: 10.1021/nl502332b
|
| [120] |
Wang L, Ding Y, Patel U, et al. (2011) Studying single nanocrystals under high pressure using an x-ray nanoprobe. Rev Sci Inst 82: 43903. doi: 10.1063/1.3584881
|
| [121] |
Xu F, Helfen L, Suhonen H, et al. (2012) Correlative Nanoscale 3D Imaging of Structure and Composition in Extended Objects. PLOS One 7: e50124. doi: 10.1371/journal.pone.0050124
|
| [122] |
McHugo S, Thompson C, Périchaud I, et al. (1998) Direct correlation of transition metal impurities and minority carrier recombination in multicrystalline silicon. Appl Phys Lett 72: 3482. doi: 10.1063/1.121673
|
| [123] |
Vyvenko OF, Buonassisi T, Istratov AA, et al. (2002) X-ray beam induced current—A synchrotron radiation based technique for the in situ analysis of recombination properties and chemical nature of metal clusters in silicon. J Appl Phys 91: 3614-3617. doi: 10.1063/1.1450026
|
| [124] |
Istratov AA, Buonassisi T, McDonald RJ, et al. (2003) Metal content of multicrystalline silicon for solar cells and its impact on minority carrier diffusion length. J Appl Phys 94: 6552. doi: 10.1063/1.1618912
|
| [125] | Buonassisi T, Istratov AA, Huer M, et al. (2005a) Synchrotron-based investigations of the nature and impact of iron contamination in multicrystalline silicon solar cells. J Appl Phys 97: 074901. |
| [126] | Buonassisi T, Istratov AA, Pickett MD, et al. (2006) Chemical natures and distributions of metal impurities in multicrystalline silicon materials. Progress in Photovoltaics: Res App 14: 512-531. |
| [127] |
Trushin M, Seifert W, Vyvenko O, et al. (2010) XBIC/μ-XRF/μ-XAS analysis of metals precipitation in block-cast solar silicon. Nucl Inst Methods Phys Res B 268: 254-258. doi: 10.1016/j.nimb.2009.09.057
|
| [128] |
Gundel P, Schubert MC, Heinz FD, et al. (2010) Impact of stress on the recombination at metal precipitates in silicon. J Appl Phys 108: 103707. doi: 10.1063/1.3511749
|
| [129] |
Fenning DP, Hofstetter J, Bertoni MI, et al. (2011) Iron distribution in silicon after solar cell processing: Synchrotron analysis and predictive modeling. Appl Phys Lett 98: 162103. doi: 10.1063/1.3575583
|
| [130] | Fenning DP, Hofstetter J, Bertoni MI, et al. (2013). Precipitated iron: A limit on gettering efficacy in multicrystalline silicon Precip. J Appl Phys 113: 044521. |
| [131] | Zuschlag M, Schwab M, Merhof D, Hahn G (2014) Transition metal precipitates in mc Si: a new detection method using 3D-FIB. Solid State Phenom 205-206: 136-141. |
| [132] |
Dietl T (2010) A ten-year perspective on dilute magnetic semiconductors and oxides. Nat Mater 9: 965-974. doi: 10.1038/nmat2898
|
| [133] |
Martinez-Criado G, Somogyi A, Ramos S, et al. (2005) Mn-rich clusters in GaN: Hexagonal or cubic symmetry? Appl Phys Lett 86: 131927. doi: 10.1063/1.1886908
|
| [134] |
Martínez-Criado G, Somogyi A, Hermann M, et al. (2004) Direct observation of Mn clusters in GaN by X-ray scanning microscopy. Jap J Appl Phys Part 2: Letter 43: 695-697. doi: 10.1143/JJAP.43.695
|
| [135] |
Sancho-Juan O, Cantarero A, Martínez-Criado G, et al. (2006) X-ray absorption near edge spectroscopy at the Mn K-edge in highly homogeneous GaMnN diluted magnetic semiconductors. Physica Status Solidi (B) Basic Res 243: 1692-1695. doi: 10.1002/pssb.200565413
|
| [136] |
Sancho-Juan O, Cantarero A, Garro N, et al. (2009) X-ray absorption near-edge structure of GaN with high Mn concentration grown on SiC. J Phys Cond Mat 21: 295801. doi: 10.1088/0953-8984/21/29/295801
|
| [137] |
Farvid SS, Hegde M, Hosein ID, et al. (2011) Electronic structure and magnetism of Mn dopants in GaN nanowires : Ensemble vs single nanowire measurements. Appl Phys Lett 99: 222504. doi: 10.1063/1.3664119
|
| [138] |
Segura-Ruiz J, Martinez-Criado G, Denker C, et al. (2014) Phase Separation in Single InxGa1-xN Nanowires Revealed through a Hard X ray Synchrotron Nanoprobe. Nano Lett 14: 1300-1305. doi: 10.1021/nl4042752
|
| [139] | Egerton RF, Li P, Malac M (2004) Radiation damage in the TEM and SEM, 35: 399-409. |
| [140] | Hitchcock AP, Dynes JJ, Johansson G, et al. (2008a) Comparison of NEXAFS microscopy and TEM-EELS for Studies of Soft Matter. Micron 39:741-748. |
| [141] | Harris WM, Lombardo JJ, Nelson GJ, et al. (2014) Three-dimensional microstructural imaging of sulfur poisoning-induced degradation in a Ni-YSZ anode of solid oxide fuel cells. Scientific Reports 4: 5246. |
| [142] |
Martinez-Criado G, Alen B, Homs A, et al. (2006) Scanning x-ray excited optical luminescence microscopy in GaN. Appl Phys Lett 89: 221913. doi: 10.1063/1.2399363
|
| [143] |
Martínez-Criado G, Homs A, Alén B, et al. (2012) Probing quantum confinement within single core- multishell nanowires. Nano Lett 12: 5829-5834. doi: 10.1021/nl303178u
|
| [144] | Paterson D, Jonge MD De, Howard DL, et al. (2011). The X-ray fluorescence microscopy beamline at the Australian synchrotron. AIP Conf Proc 1365:219-222. |
| [145] | Huang X, Lauer K, Clark JN, et al. (2015). Fly-scan ptychography. Scientific Reports 5:9074. |
| [146] |
Jonge MD De, Ryan G, Jacobsen CJ (2014) X-ray nanoprobes and diffraction-limited storage rings : opportunities and challenges of fluorescence tomography of biological specimens. J Synch Rad 21:1031-1047. doi: 10.1107/S160057751401621X
|
| [147] |
Guillamet R, Lagay N, Mocuta C, et al. (2013) Micro-characterization and three imensional modeling of very large waveguide arrays by selective area growth for photonic integrated circuits. J Cryst Growth 370: 128-132. doi: 10.1016/j.jcrysgro.2012.09.053
|
| [148] |
Decobert J, Guillamet R, Mocuta C, et al. (2013) Structural characterization of selectively grown multilayers with new high angular resolution and sub-millimeter spot-size x-ray diffractometer. J Cryst Growth 370: 154-156. doi: 10.1016/j.jcrysgro.2012.06.011
|
| [149] |
Bussone G, Schäfer-Eberwein H, Dimakis E, et al. (2015) Correlation of Electrical and Structural Properties of Single As-Grown GaAs Nanowires on Si (111) Substrates. Nano Lett 15: 981. doi: 10.1021/nl5037879
|
| [150] | Beutier G, Verdier M, De Boissieu M, et al. (2013b) Combined coherent x-ray micro-diffraction and local mechanical loading on copper nanocrystals. J Phys Conf Series 425: 132003. |
| [151] | Mondiali V, Bollani M, Cecchi S, et al. (2014A) Dislocation engineering in SiGe on periodic and aperiodic Si(001) templates studied by fast scanning X-ray nanodiffraction. Appl Phys Lett 104: 021918. |
| [152] | Mondiali V, Bollani M, Chrastina D, et al. (2014B) Strain release management in SiGe/Si films by substrate patterning. Appl Phys Lett 105: 242103. |
| [153] | Als-Nielsen J, McMorrow D (2011) Elements of Modern X-ray Physics. (2nd Edition), Wiley. |
| [154] |
Riekel C, Davies JD (2005) Applications of synchrotron radiation micro-focus techniques to the study of polymer and biopolymer fibers. Curr Opin Colloid In 9: 396-403. doi: 10.1016/j.cocis.2004.10.004
|
| [155] |
Larson BC, Yang W, Ice GE, et al. (2002) Three-dimensional X-ray structural microscopy with submicrometre resolution. Nature 415: 887-890. doi: 10.1038/415887a
|
| [156] |
Budai JD, Yang WG, Tamura N, et al. (2003) X-ray microdiffraction study of growth modes and crystallographic tilts in oxide films on metal substrates. Nature Materials 2: 487-492. doi: 10.1038/nmat916
|
| [157] | Schmidbauer M (2004) X-Ray Diffuse Scattering from Self-Organized Mesoscopic Semiconductor Structures. Springer Tracts in Modern Physics 199. |
| [158] |
Hrauda N, Zhang JJ, Groiss H, et al. (2013) Strain relief and shape oscillations in site-controlled coherent SiGe islands. Nanotechnology 24: 335707. doi: 10.1088/0957-4484/24/33/335707
|
| [159] | Barbier A, Mocuta C, Belkhou R (2012) Selected Synchrotron Radiation Techniques, chapter in Enciclopedia of Nanotechnology. ed. B. Bhushan, 2322-2344. Springer. |
| [160] |
Holy V, Mundboth K, Mocuta C, et al. (2008) Structural characterization of self-assembled semiconductor islands by three-dimensional X-ray diffraction mapping in reciprocal space. Thin Solid Films 516: 8022-8028. doi: 10.1016/j.tsf.2008.04.009
|
| [161] |
Mocuta C, Barbier A, Ramos AV, et al. (2009) Crystalline structure of oxide-based epitaxial tunnel junctions. Eur Phys J Special Topics 167: 53-58. doi: 10.1140/epjst/e2009-00936-5
|
| [162] |
Murray CE, Noyan IC, Mooney PM, et al. (2003) Mapping of strain fields about thin film structures using x-ray microdiffraction. Appl Phys Lett 83: 4163. doi: 10.1063/1.1628399
|
| [163] |
Murray CE, Saenger KL, Kalenci O, et al. (2008) Submicron mapping of silicon-on-insulator strain distributions induced by stressed liner structures. J Appl Phys 104: 013530. doi: 10.1063/1.2952044
|
| [164] |
Murray CE, Yan HF, Noyan IC, et al. (2005) High-resolution strain mapping in heteroepitaxial thin-film features. J Appl Phys 98: 013504. doi: 10.1063/1.1938277
|
| [165] |
Murray CE, Ying A, Polvino SM, et al. (2011) Nanoscale silicon-on-insulator deformation induced by stressed liner structures. J Appl Phys 109: 083543. doi: 10.1063/1.3579421
|
| [166] |
Vartaniants IA, Zozulya AV, Mundboth K, et al. (2008) Crystal truncation planes revealed by three-dimensional reconstruction of reciprocal space. Phys Rev B 77: 115317. doi: 10.1103/PhysRevB.77.115317
|
| [167] |
Yefanov OM, Zozulya AV, Vartaniants IA, et al. (2009) Coherent diffraction tomography of nanoislands from grazing-incidence small-angle x-ray scattering. Appl Phys Lett 94: 123104. doi: 10.1063/1.3103246
|
| [168] | Zozulya AV, Yefanov OM, Vartaniants IA, et al. (2009) Imaging of nanoislands in coherent grazing-incidence small-angle x-ray scattering experiments. Phys Rev B 78: 121304R. |
| [169] |
Nanver LK, Jovanovis V, Biasotto C, et al. (2011) Integration of MOSFETs with SiGe dots as stressor material. Solid State Electronics 60: 75-83. doi: 10.1016/j.sse.2011.01.038
|
| [170] |
Rodrigues MS, Cornelius TW, Scheler T, et al. (2009) In situ observation of the elastic deformation of a single epitaxial SiGe crystal by combining atomic force microscopy and micro x-ray diffraction. J Appl Phys 106: 103525. doi: 10.1063/1.3262614
|
| [171] |
Cornelius TW, Davydok A, Jacques VLR, et al. (2012) In situ three-dimensional reciprocal-space mapping during mechanical deformation. J Synch Rad 19: 688-694. doi: 10.1107/S0909049512023758
|
| [172] | Cornelius TW, Mastropietro F, Thomas O, et al. (2013) In situ nanofocused X-ray diffraction combined with scanning probe microscopy, chapter in X-ray diffraction: Structure, Principles and Applications, ed. Shih K, 223-259, Nova Science Publisher. |
| [173] | Kang HC, Yan H, Chu YS, et al. (2013). Oxidation of PtNi nanoparticles studied by a scanning X-ray fluorescence microscope with multi-layer Laue lenses. Nanoscale 5:7184. |
| [174] | Chu YS (2010) Preliminary Design Report for the Hard X-ray (HXN) Nanoprobe Beamline. National Synchrotron Light Source II, Brookhaven National Laboratory, LT-C-XFD-HXN-PDR-001. |
| [175] |
Nazaretski E, Lauer K, Yan H, et al. (2015). Pushing the limits: an instrument for hard X-ray imaging below 20 nm. J Synch Rad 22:336-341. doi: 10.1107/S1600577514025715
|
| [176] | Vogt S, Lanzirotti A (2013) Trends in X-ray Fluorescence Microscopy. Synchrotron Radiation News 26: 32-38. |
| [177] |
Deng J, Vine DJ, Chen S, et al. (2015) Simultaneous cryo X-ray ptychographic and fluorescence microscopy of green algae. Proc Nat Acad Sci 112: 2314-2319. doi: 10.1073/pnas.1413003112
|
| [178] | Que EL, Bleher R, Duncan FE, et al. (2015) Quantitative mapping of zinc fluxes in the mammalian egg reveals the origin of fertilization-induced zinc sparks. Nature Chem 7: 130-139. |
| [179] |
Davies R, Burghammer M, Riekel C (2009) A combined microRaman and microdiffraction set-up at the European Synchrotron Radiation Facility ID13 beamline. J Synch Rad 16: 22-29. doi: 10.1107/S0909049508034663
|
| [180] |
Bernal S, Provis JL, Rose V, et al. (2013). High-resolution X-ray diffraction and fluorescence microscopy characterization of alkali-activated slag-metakaolin binders. J Am Ceramic Soc 96: 1951-1957. doi: 10.1111/jace.12247
|
| [181] | Andrews JC, Weckhuysen BM (2013) Hard X-ray Spectroscopic Nano-Imaging of Hierarchical Functional Materials at Work. Chem Phys Chem 14: 3655. |
| [182] |
Barrea RA, Gore D, Kujala N (2010) Fast-scanning high-flux microprobe for biological X-ray fluorescence microscopy and microXAS. J Synch Rad 17: 522-529. doi: 10.1107/S0909049510016869
|
| [183] | Mocuta C, Richard MI, Fouet J, et al. (2013B) Fast pole figure acquisition using area detectors at DiffAbs beamline - Synchrotron SOLEIL. J Appl Cryst 46: 1842-4853. |
| [184] | Eriksson M, van der Veen JF, guest editors (2014) Special issue on Diffraction-Limited Storage Rings and New Science Opportunities. J Synch Rad 21: Part 5. |
| [185] |
Hettel R (2014) Diffraction-limited storage rings DLSR design and plans : an international overview diffraction-limited storage rings. J Synch Rad 21:843-855. doi: 10.1107/S1600577514011515
|
| [186] | Mimura H, Handa S, Kimura T, et al. (2010) Breaking the 10nm barrier in hard-X-ray focusing. Nature Physics 6:122-125. |
| [187] |
Yamauchi K, Mimura H, Kimura T, et al. (2011) Single-nanometer focusing of hard x-rays by Kirkpatrick - Baez mirrors. J Phys: Condensed Matter 23:394206. doi: 10.1088/0953-8984/23/39/394206
|
| [188] |
Yan H, Conley R, Bouet N, et al. (2014) Hard x-ray nanofocusing by multilayer Laue lelenses. J Phys D: Appl Phys 47: 263001. doi: 10.1088/0022-3727/47/26/263001
|
| [189] |
Döring F, Robisch L, Eberl C, et al. (2013) Sub-5 nm hard x-ray point focusing by a combined Kirkpatrick-Baez mirror and multilayer zone plate. Opt Express 21: 19311-19323. doi: 10.1364/OE.21.019311
|
| [190] |
Mohacsi I, Vartiainen I, Guizar-Sicairos M, et al. (2015) High resolution double-sided diffractive optics for hard X-ray microscopy. Opt Express 23:776-786. doi: 10.1364/OE.23.000776
|
| [191] |
Schroer CG, Falkenberg G (2014) Hard X-ray nanofocusing at low-emittance synchrotron radiation sources. J Sync Rad 21:996-1005. doi: 10.1107/S1600577514016269
|
| [192] |
Thibault P, Guizar-Sicairos M, Menzel A (2014) Coherent imaging at the diffraction limit. J Synch Rad 21: 1011-1018. doi: 10.1107/S1600577514015343
|
| [193] | Schlichting I, White WE, Yabashi M, guest editors (2015) Special issue on X-ray Free-Electron Lasers, Guest Editors: J Synch Rad 22:Part 3. |
| [194] | Solé VA, Papillon E, Cotte M, et al. (25007) A multiplatform code for the analysis of energy-dispersive X-ray fluorescence spectra. Spectrochim Acta B 62: 63-68. |
| [195] |
Ashiotis G, Deschildre A, Nawaz Z, et al. (2015) The fast azimuthal integration Python library: pyFAI. J Appl Cryst 48: 510-519. doi: 10.1107/S1600576715004306
|
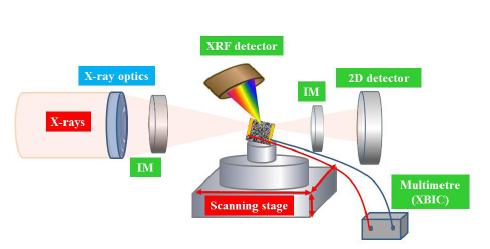
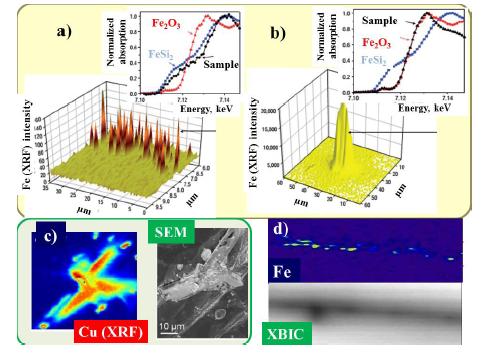
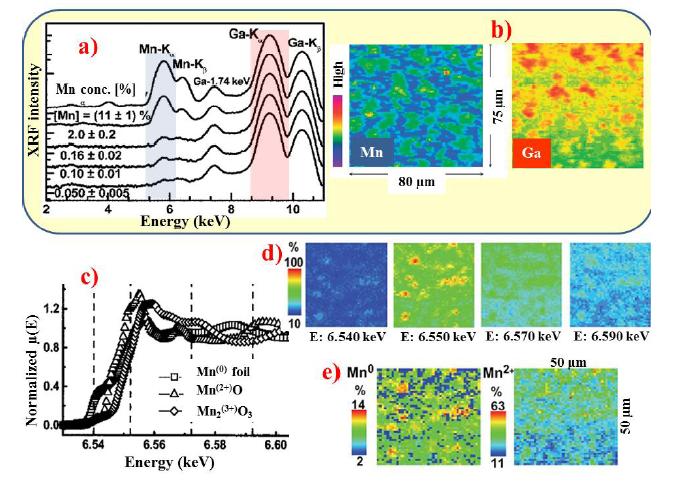
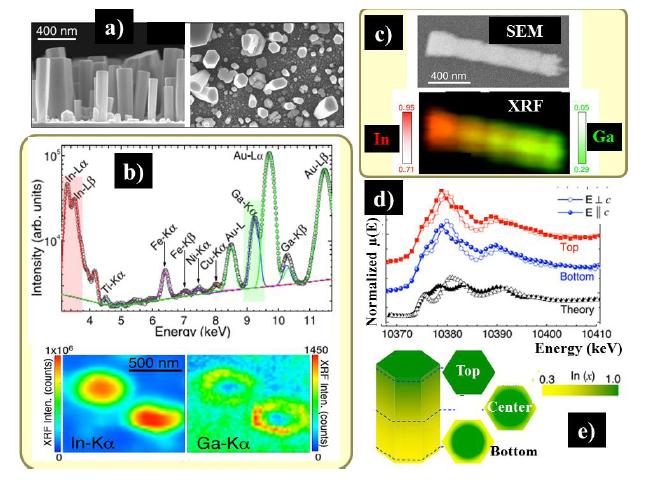
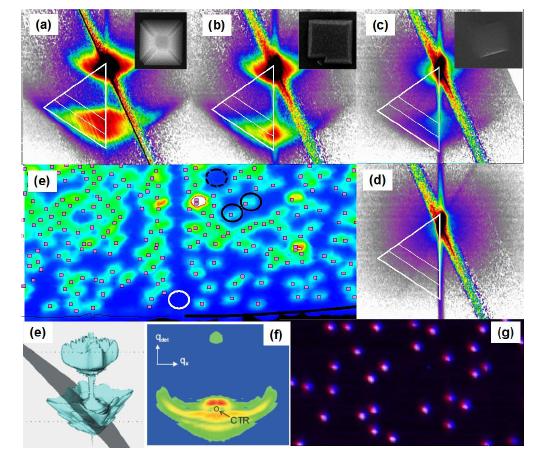
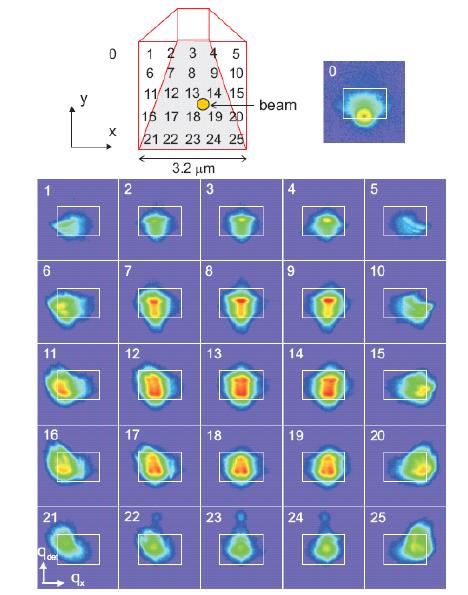
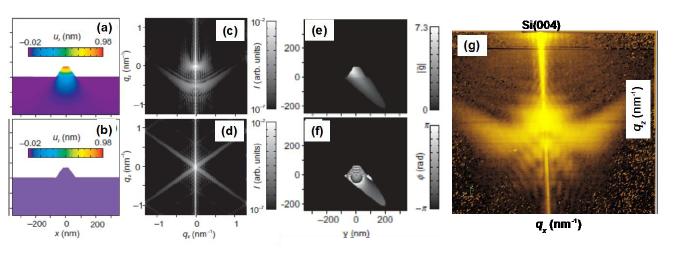
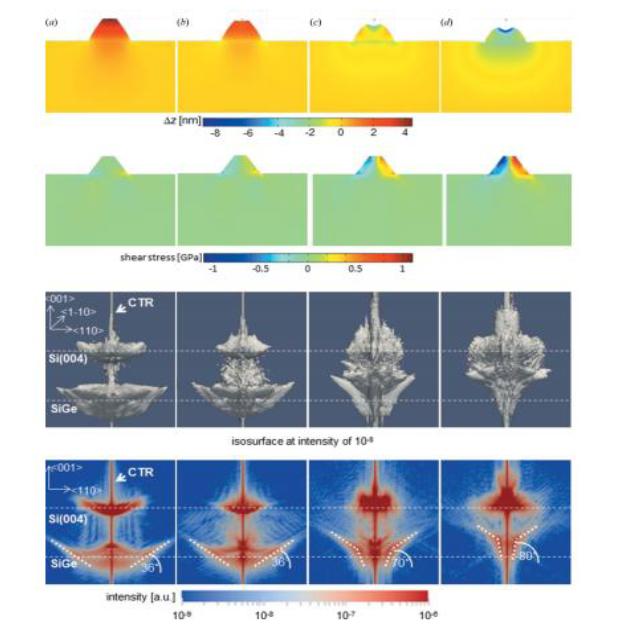
Figures(8)

Andrea Somogyi, Cristian Mocuta. Possibilities and Challenges of Scanning Hard X-ray Spectro-microscopy Techniques in Material Sciences[J]. AIMS Materials Science, 2015, 2(2): 122-162. doi: 10.3934/matersci.2015.2.122







 DownLoad:
DownLoad: